
We propose a Few-shot Dynamic Neural Radiance Field (FDNeRF), the first NeRF-based method capable of reconstruction and expression editing of 3D faces based on a small number of dynamic images. Unlike existing dynamic NeRFs that require dense images as input and can only be modeled for a single identity, our method enables face reconstruction across different persons with few-shot inputs. Compared to state-of-the-art few-shot NeRFs designed for modeling static scenes, the proposed FDNeRF accepts view-inconsistent dynamic inputs and supports arbitrary facial expression editing, i.e., producing faces with novel expressions beyond the input ones. To handle the inconsistencies between dynamic inputs, we introduce a well-designed conditional feature warping (CFW) module to perform expression conditioned warping in 2D feature space, which is also identity adaptive and 3D constrained. As a result, features of different expressions are transformed into the target ones. We then construct a radiance field based on these view-consistent features and use volumetric rendering to synthesize novel views of the modeled faces. Extensive experiments with quantitative and qualitative evaluation demonstrate that our method outperforms existing dynamic and few-shot NeRFs on both 3D face reconstruction and expression editing tasks. Our code and model will be available upon acceptance.
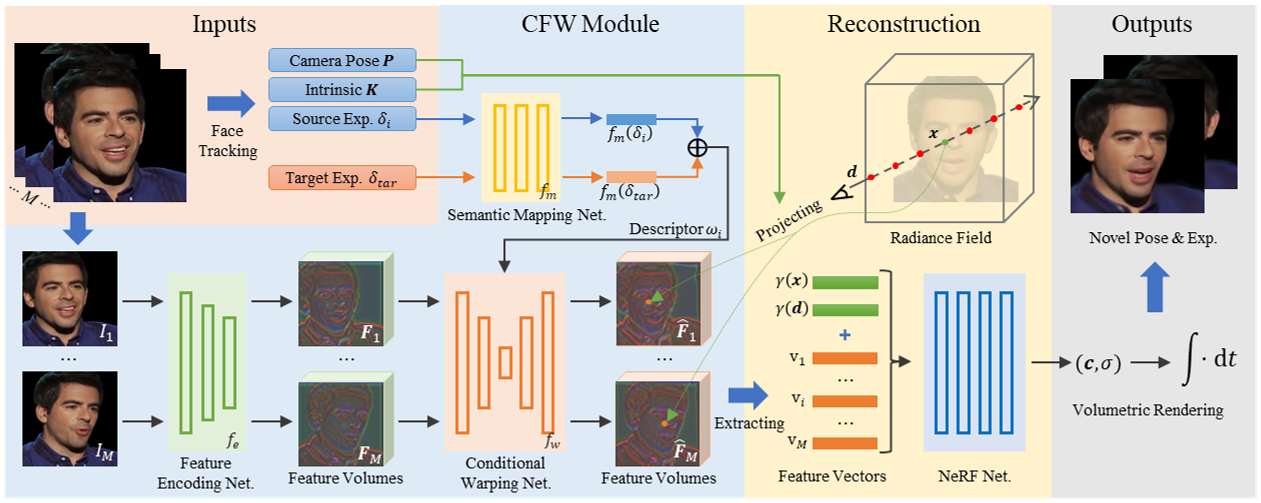
Overview of our FDNeRF. Given few-shot dynamic images, face tracking is implemented to estimate relevant expression parameters, camera poses, and intrinsic matrix in the preprocessing stage. In the CFW module, we employ feature encoding network to extract a deep feature volume for each image, and semantic mapping network to generate a motion descriptor based on source and target expression parameters. The descriptor is then used to guide the conditional warping network to produce warped feature volumes. During reconstruction, we project the query point to each image plane and extract aligned feature vectors. These vectors, along with the position and direction of the point, are fed into NeRF network to infer color and density. Finally, volumetric rendering is performed to synthesize novel view images.
@article{zhang2022fdnerf,
title={FDNeRF: Few-shot Dynamic Neural Radiance Fields for Face Reconstruction and Expression Editing},
author={Zhang, Jingbo and Li, Xiaoyu and Wan, Ziyu and Wang, Can and Liao, Jing},
journal={arXiv preprint arXiv:2208.05751},
year={2022}
}